

At Wehkamp we've been using machine learning for a while now. We're training models in Databricks (Spark) and Keras. This produces a Keras file that we use to make the actual predictions. Training is one thing, but getting them to production is quite another!
I teamed up with Jesse Bouwman, one of our data scientists, to see if we could get 2 of our image classifier models working on an AWS Lambda. The main problem we've faced was size: our program was way too big to actually fit into a lambda. This blog shows how we've dealt with that problem.
Setup
Our Digital Asset Management (DAM) service sends assets to an S3 bucket. Upon upload, we would like to classify the images. The upload will automatically trigger the lambda with the machine learning models. We'll send the images through the classifiers and save the results as S3 metadata on the objects.
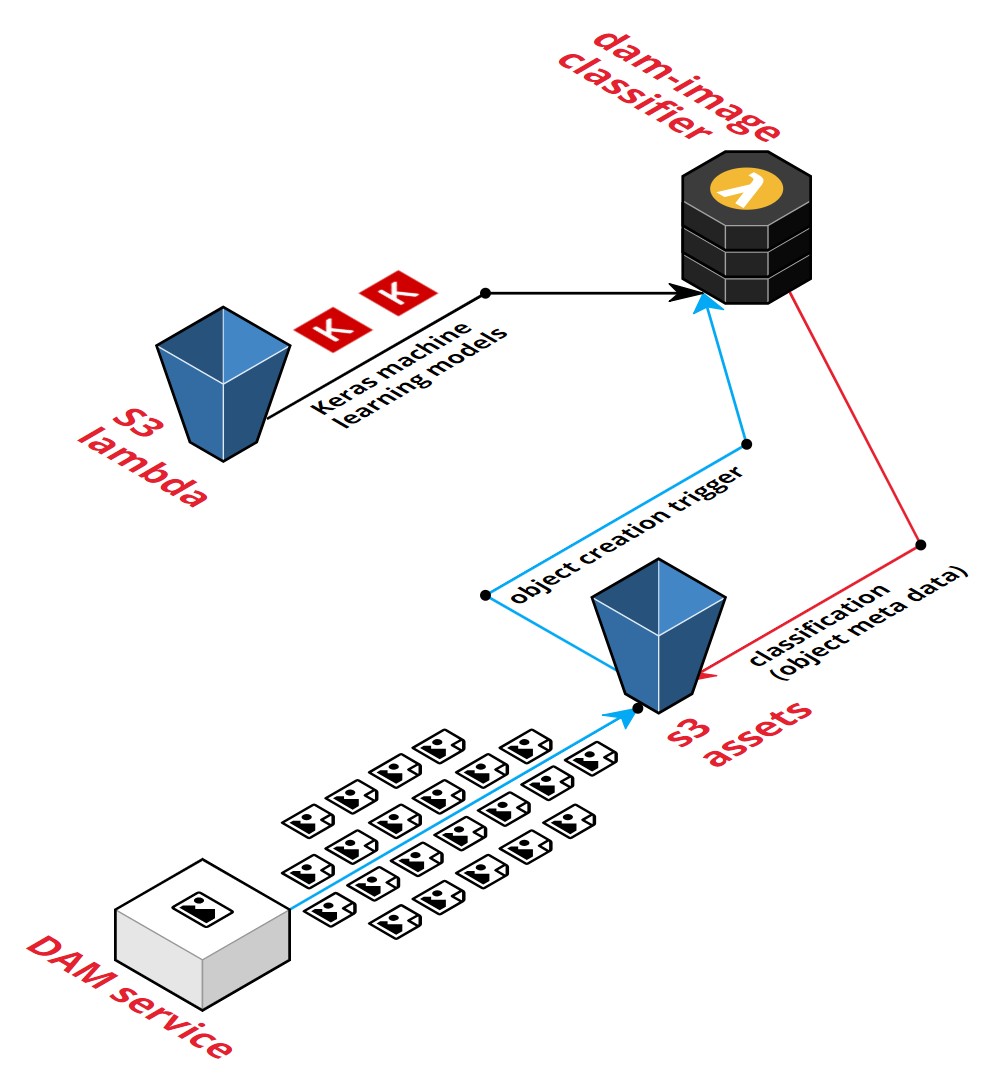
Because we use Databricks we're familiar with Python, so we decided to create the lambda in Python as well.
Lambda: the sky is the limit?
Well... no. There are some serious size limitations in AWS Lambda:
- The deployment package size has a hard limit of
262144000 bytes, that's 262 MB. So the unzipped size of your package — including the layers — cannot be greater than this number. - The temp storage limit is 512 MB.
- The memory limit is 3008 MB.
Our program has the following dependencies:
tensorflow==1.8.0
Keras==2.2.4
pillow==5.4.1
numpy==1.16.3
colorgram.py==1.2.0
webcolors==1.8.1
boto3==1.9.137These Python packages should be shipped with our Lambda. When we install them into a single directory we end up with 415 MB. The models we're using is are Keras H5 models that are both 159 MB. When we round the size of our actual code to a single MB, we come to the following conclusion:
program + packages + models =
1 MB + 415 MB + 318 MB =
734 MB
= way too much for an AWS Lambda!
AWS Layer for TF+Keras+PIL
We're not the first people that have problems with the size limitations of AWS Lambda. Anton Paquin has been experimenting with a Lambda Layer that holds TensorFlow, Keras, and PIL and is under the 250 MB limit!
The layer we'll be using is arn:aws:lambda:eu-west-1:347034527139:layer:tf_keras_pillow:1 and is only 230 MB in size. It uses TensorFlow 1.8.0 because this currently is the latest version that is small enough for a Lambda (version 1.12 is 282 MB).
This means we need to ship less packages. The layer also includes Boto3 for S3 communication, so we don't have to load it.
Sideloading packages
We still need to ship the following packages:
numpy==1.16.3
colorgram.py==1.2.0
webcolors==1.8.1One of the packages is also dependent on Pillow, but because of the layer we don't have to ship it. If we calculate the size of the packages we see that we only need to ship 81 MB! But how are we going to do this?
Package 'em up
We are - for lack of a better term - going to sideload our packages. We're going to zip them up (to save space) and deploy them when the lambda is started.
First, we'll need to package the dependencies up in a new zip file. Let's create a new requirements-lambda.txt with the packages we need to ship and let's run this script:
#!/bin/bash
name=$(basename -s .git `git config --get remote.origin.url`)
if [ -d "deploy" ]; then rm -Rf deploy; fi
mkdir deploy
pip install -r requirements-lambda.txt -t deploy/requirements-lambda/
cd deploy/requirements-lambda
rm -r PIL
rm -r Pillow*
zip -9 -r ../$name-requirements.zip .
cd ..
rm -r requirements-lambdaThe zip is only 15.7 MB, which means it fits in our Lambda. So we can actually ship it with our Lambda. (Is your zip bigger? No worries, just read on).
Un(z/sh)ip it
We'll ship it with the Lambda package in the root. When the Lambda is started, we'll need to unzip it. Let's create a new setup.py that will unpack the dependencies and add them to the program:
import os
import sys
import zipfile
pkgdir = '/tmp/requirements'
zip_requirements = 'lambda-requirements.zip'
if os.environ.get("AWS_EXECUTION_ENV") is not None:
if not os.path.exists(pkgdir):
root = os.environ.get('LAMBDA_TASK_ROOT', os.getcwd())
zip_requirements = os.path.join(root, zip_requirements)
zipfile.ZipFile(zip_requirements, 'r').extractall(pkgdir)
sys.path.append(pkgdir)In your handler, just use import setup as the first line and the unzipped packages are used.
Too big to ship with the package?
What if the requirements package is bigger than 20 MB? Or what if you want to be able to edit the package in the online editor? (Then the uploaded package (without the layers) should be under 3 MB).
We could use S3 to ship our dependencies! Use the same package routine, but in your setup.py, use:
import boto3
import os
import sys
import zipfile
REQUIREMENTS_BUCKET_NAME = ''
REQUIREMENTS_KEY = ''
pkgdir = '/tmp/requirements'
zip_requirements = '/tmp/lambda-requirements.zip'
sys.path.append(pkgdir)
if os.environ.get("AWS_EXECUTION_ENV") is not None:
if not os.path.exists(pkgdir):
s3 = boto3.resource('s3')
bucket = s3.Bucket(REQUIREMENTS_BUCKET_NAME)
bucket.download_file(REQUIREMENTS_KEY, zip_requirements)
zipfile.ZipFile(zip_requirements, 'r').extractall(pkgdir)
os.remove('zip_requirements')
sys.path.append(pkgdir)Lazy-loading the models from S3
Our models were already "living" in S3. The last step of our Databricks training script is to send the Keras models to an S3 bucket. We cannot ship the models with the package anyway, as they are way too big. And it kind of makes sense to see the models as data.
Let's use lazy loading to load the models into the lambda:
import boto3
import keras
import os
MODEL_BUCKET = ''
cache = {}
def get_model(key):
if key in cache:
return cache[key]
local_path = os.path.join('/tmp', key)
# download from S3
if not os.path.isfile(local_path):
bucket=s3.Bucket(MODEL_BUCKET)
bucket.download_file(key, local_path)
cache[key] = keras.models.load_model(local_path)
return cache[key]In the actual solution, we're using a JSON config file to load the models, but the idea is the same.
So...
The size of the lambda is limited, but we can work around it. Our lambda layout looks a little like this:

There is not much space left for another model. A better idea might be to use a single model per lambda. In that case, we should configure our CI/CD to redeploy the lambda for each model — but that’s for another time.
It is a pity that we have to jump to hoops to load a bigger function. I really hope AWS will allow us to at least use bigger packages.