

This week we've been working on processing the access logs from Cloudflare with Databricks (Spark). We now have a job that generates a huge CSV file (+1GB) and sends it on towards by FTP for further processing with an external tool. Creating a DataFrame with the right data was easy. Now, let's explore how to do a CSV export, secrets management and an FTP transfer!
A big shout-out to Can Mentes and Sjoerd Jongmans, our SEO gurus, for participating on this code.
1. But I just want 1 CSV file...
The default CSV writer employed by Spark does not do what we want: it creates multiple files! It does so for a good reason: so it can parallelize the output writes. Today we just need a single file! That's why we're using Pandas:
file="/tmp/my.csv"
df.toPandas().to_csv(file, sep=',', header=True, index=False)This code will produce a single CSV file and write it to the temp directory. It will take a while and you probably need enough memory.
Note, if you want all fields to be quoted, you can use the option quoting=csv.QUOTE_ALL.
2. How to keep the FTP username and password secret?
Now that we have our CSV file, we can send it by FTP. But we need to figure out how to store the username and password securely.
Fortunately Databricks provides an excellent way to manage these types of secrets. First, we'll create a group (of users). Then we'll add the secrets using the Databricks CLI. We need to make sure that the secrets can be managed by the group. Finally, we'll use the secrets in our notebook.
2.1 Group
These secrets should be accessible for every member of the SEO team, so let's create a group for that team:
- Click on the gear icon in the bottom left part of the side menu.
- Click on Admin Console
- Click on the Groups tab
- Click on the Create Group button
- Enter a Name (in my case SEO)
- Click on the Create button
- Add all the users to the group.
2.2 Databricks CLI
Installing the Databricks CLI is easy. Make sure you have Python and PIP installed and run the following commands in your favourite terminal to install it:
pip install databricks-cliNow, let's generate a new access token:
- Click on the gear icon in the bottom left part of the side menu.
- Click on User Settings.
- You should now land in the Access Tokens tab and you can click Generate New Token.
- Add a Comment.
- In my case I cleared the Lifetime (days) field. Default token life is 90 days.
- Click the Generate button.
Let's configure the token by running in the terminal:
databricks configure --tokenIn this step you'll get prompts for the Databricks Host and for the token. Just paste them to the terminal.
2.3 Creating secrets 🤫
First, we need to configure a secrets scope, in which we'll store the secrets. Let's tie it to the group. Paste the following in your terminal:
databricks secrets create-scope --scope team-seo
databricks secrets put-acl --scope team-seo --principal SEO --permission MANAGENext, we can add the secrets:
databricks secrets put --scope team-seo --key MyFtpUsername --string-value 'MyUserName'
databricks secrets put --scope team-seo --key MyFtpPassword --string-value 'P@ssw0rd'Note: when you omit --string-value and editor will pop up and you can add larger blobs to that editor.
2.4 Reading the secrets 🤫
Now that we've store our secrets, let's read them into variables for later use:
my_ftp_user_name = dbutils.secrets.get("team-seo", "MyFtpUsername")
my_ftp_password = dbutils.secrets.get("team-seo", "MyFtpPassword")3. FTP
Everything is ready for us to send the file onwards over the FTP. We'll use the ftplib library to handle our FTP connection:
from ftplib import FTP
from pathlib import Path
file_path = Path(file)
with open(file_path, 'rb') as fl:
with FTP('my.ftp.example', my_ftp_user_name , my_ftp_password) as ftp:
# navigate to right FTP folder
ftp.cwd("ktt")
# write the file:
ftp.storbinary(f'STOR {file_path.name}', fl)
More resilience
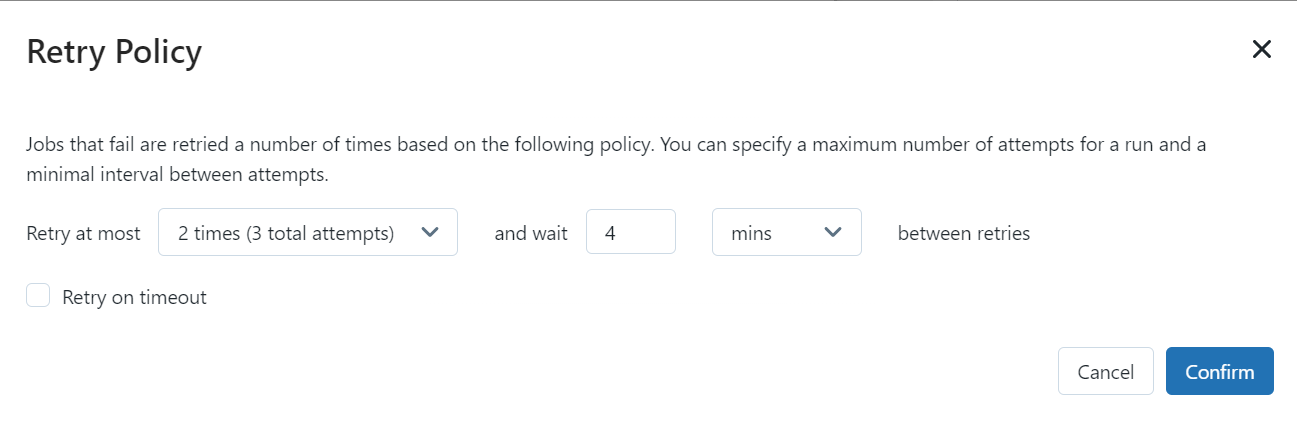
We use our FTP connection in a job that runs on AWS spot instances. This means that our job may terminate or crash. That's why we implemented 2 retries with 4 minutes apart.
Conclusion
Pandas make it easier to write CSV files. Secrets management with Python is quite nice, but you might want to think of a good strategy in naming your groups and scopes. Especially when you organization is expanding, this might become messy quite quickly. I had never worked with FTP in Python before and I really like their simple client.
Changelog
- added the more resilience section.
- the new Databricks interface has the options on a different location.
- initial article.