

We're currently in the business of moving from Mesos/Marathon to Kubernetes. As we have a microservices environment we can move service by service. We have multiple clusters running, so I need to track which teams have which services (still) running on Mesos/Marathon.
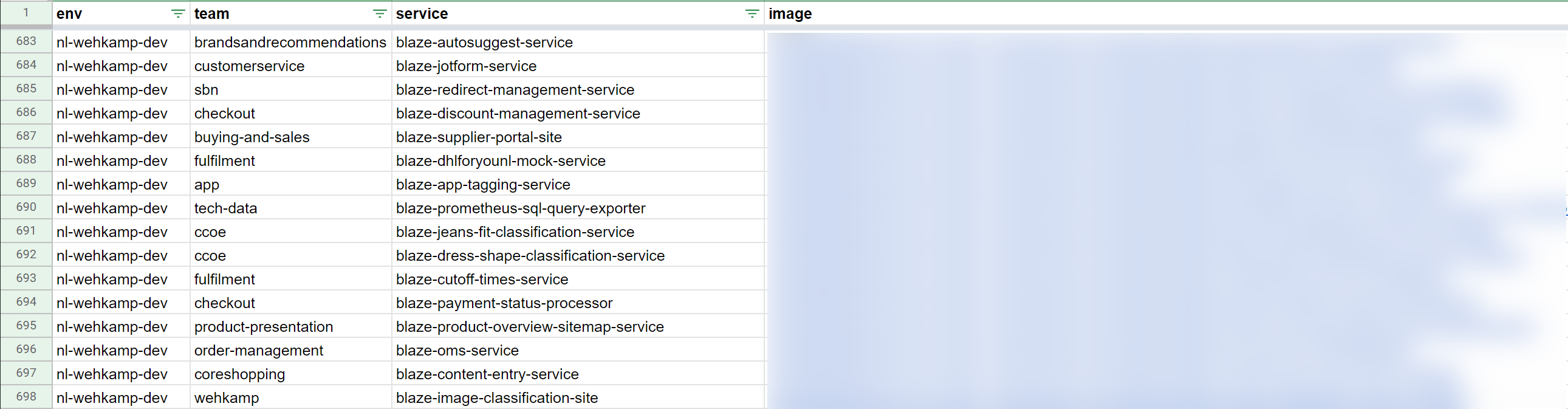
Let's see if we can lift the data out of the system using the Marathon API, JQ and cURL. Our end goal is to get the following CSV:
Packages
If you are on a Debian based machine like Ubuntu, you can install the package we use like this:
sudo apt-get update
sudo apt-get install jq curlEmpty CSV File
First, we're going to create a CSV with the fields: env, team, service and image. The env is just a name we will give to identify the environment (we won't be taking that from the Marathon API). Now let's create the empty CSV file first:
#!/usr/bin/env bash
# shellcheck disable=SC2207
results_file="marathon.csv"
echo "env,team,service,image" > "$results_file"We're writing the file using a redirection operator.
Query Marathon
What does the Marathon API have in store? Well, it provides an /v2/apps endpoint which will return the definitions of all the apps that are currently running on that service:
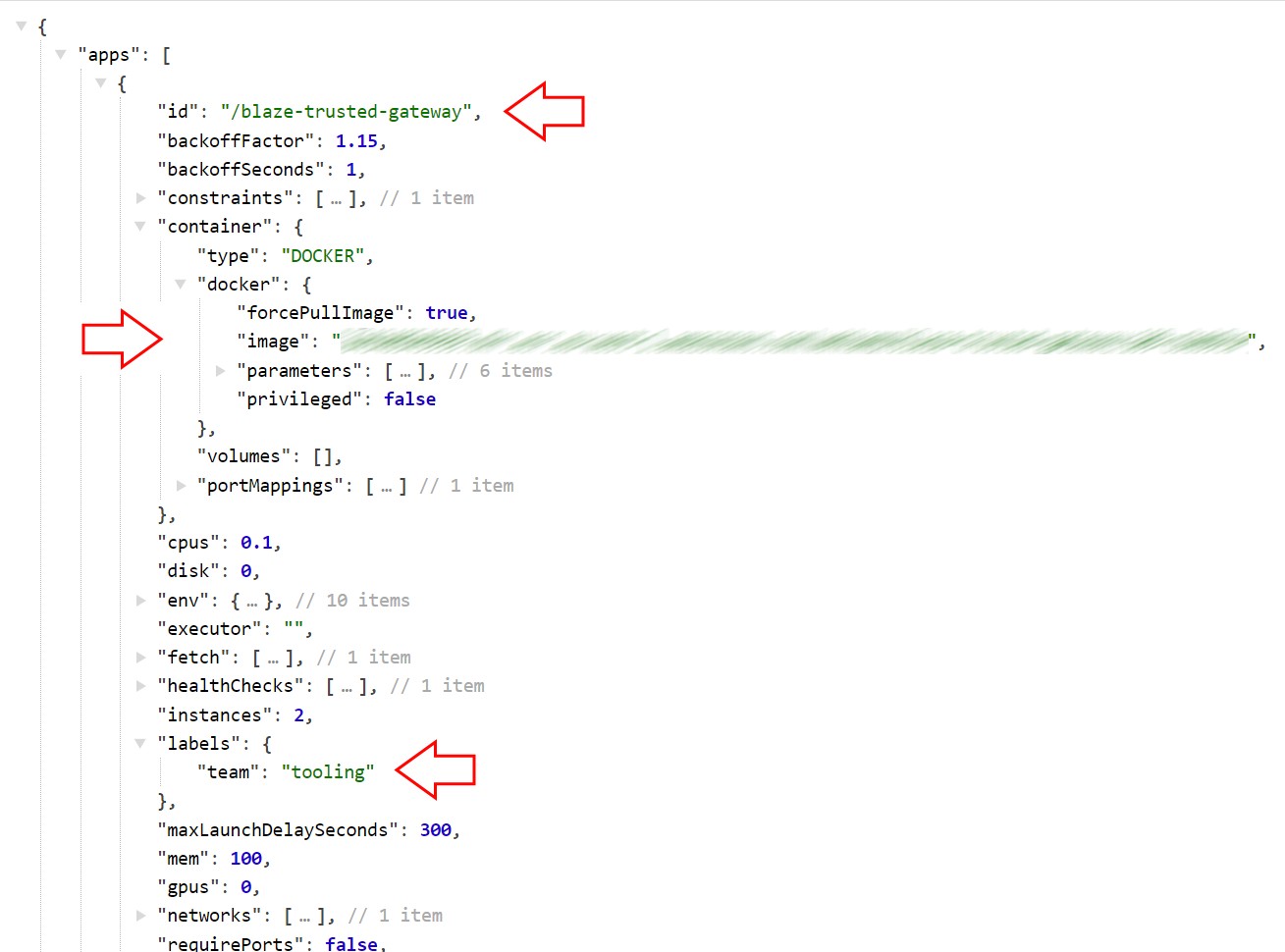
Next, let's add a function to query the Marathon API. We need to supply the env, host and results_file as positional parameters.
function query_marathon {
env=$1
host=$2
results_file=$3
api_url="http://$host:8080/v2/apps"
curl -Ss "$api_url" | \
jq --raw-output "
.apps[] |
[
\"$env\",
.labels.team,
(.id | sub(\"^/\";\"\")),
.container.docker.image
] |
@csv
" \
>> "$results_file"
}Here we use cURL to call the API and JQ to parse the result to a CSV. Notice how we use a regular expression to get rid of the forward slash of the service name.
The Loop
We want to query multiple environments, so let's create an associative array that stores the names of every environment and the host name.
declare -A hosts=(
["label1-dev"]="label.one.dev"
["label1-test"]="label.one.test"
["label1-prod"]="label.one.prod"
["label2-dev"]="label.two.dev"
)The last thing we need to do is build a loop around it, so our code becomes:
#!/usr/bin/env bash
# shellcheck disable=SC2207,SC2059
declare -A hosts=(
["label1-dev"]="label.one.dev"
["label1-test"]="label.one.test"
["label1-prod"]="label.one.prod"
["label2-dev"]="label.two.dev"
)
results_file="marathon.csv"
function query_marathon {
env=$1
host=$2
results_file=$3
api_url="http://$host:8080/v2/apps"
curl -Ss "$api_url" | \
jq --raw-output "
.apps[] |
[
\"$env\",
.labels.team,
(.id | sub(\"^/\";\"\")),
.container.docker.image
] |
@csv
" \
>> "$results_file"
}
# write the csv header
echo "env,team,service,image" > "$results_file"
# sort keys
envs=( $(echo "${!hosts[@]}" | tr ' ' '\n' | sort) )
# loop
for env in "${envs[@]}"
do
echo "Processing: $env"
host="${hosts[$env]}"
query_marathon "$env" "$host" "$results_file"
done
echo "Finished"
echo ""Enjoy!
Changelog
- 2023-01-17 Instead of
jq,yqwas used, which is a similar tools, but for parsing YAML. I've changedyqforjq --raw-outputto get the same result.